Розробка програмного забезпечення для високопродуктивної обчислювальної системи із використанням мови C та технології MPI
Зміст
Курсова робота
по дисципліні “Паралельні і розподілені обчислення”
ЗАВДАННЯ НА КУРСОВУ РОБОТУ
по дисципліні: «Паралельні та розподілені обчислення»
Розробка програмного забезпечення для високопродуктивної обчислювальної системи із використанням мови C та технології MPI.
Початкові дані:
Необхідно вирішити векторно-матричні завдання для системи з загальною пам’яттю при P=4 та P=8
Завдання:
A = B*(MC*MD) – X
ПЕРЕЛІК ГРАФІЧНОЇ ДОКУМЕНТАЦІЇ
1. Структура паралельної обчислювальної системи із загальною пам’яттю.
2. Схеми взаємодії процесів для кожного із завдань.
3. Блок-схема алгоритму виконання одного з процесів.
4. Блок-схема алгоритму виконання програми для завдання.
Технічне завдання
Розробити і описати паралельний математичний алгоритм рішення математичного вираження :
A = B * (MC*MD) – X
Побудувати алгоритм для структури ПОС з локальною пам’яттю. (P=4)
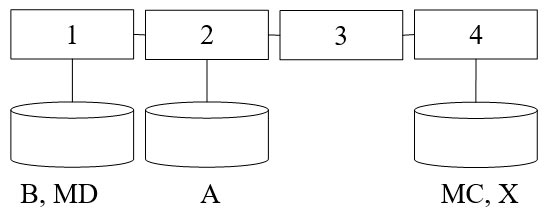
Рис. 1 – Структура ПОС з локальною пам’яттю.
Побудувати алгоритм для структури ПВС з локальною пам’яттю. (P=8)
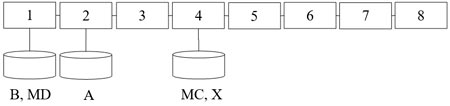
Рис. 2 – Структура ПОС з локальною пам’яттю.
• Виконати розробку програми для ПОС.
• Використовувати засоби що надаються мовою C і бібліотекою MPI.
• Побудувати паралельний математичний алгоритм.
• Побудувати алгоритм задачі.
• Побудувати алгоритм основної програми.
• Виконати дослідження ефективності реальної ПОС при рішенні заданої задачі по параметрах:
– P – кількість процесорів
– N – розмірність завдання
• При цьому обчислити такі величини:
– Т1 – час рахунку в одно-процесорному варіанті
– Тp – час рахунку при використанні P процесорів
– Ку = Т1 / Тp – коефіцієнт прискорення
РОЗДІЛ 1. Реалізація семафорів в мовах паралельного програмування
1.1. Поняття задачі
У мові Ада завдання – це конструкція, використовувана для визначення послідовності дій, яка може виконуватися паралельно з іншими послідовностями дій. Паралельне виконання завдань розуміється в тому сенсі, що кожне завдання виконується окремим логічним процесором. Різні завдання(на різних логічних процесорах) виконуються незалежно, за винятком моментів синхронізації, т. е. коли завдання зв’язуються один з одним. Паралельне виконання завдань може бути реалізоване на багатопроцесорній системі або змодельоване шляхом виконання, що чергується, на єдиному фізичному процесорі.
Завдання може містити входи. Вхід завдання може бути викликаний іншими завданнями. Завдання приймає виклик входу шляхом виконання оператора прийняття цього входу. Синхронізація двох завдань відбувається за допомогою рандеву між завданням, що викликає вхід, і завданням, що приймає цей виклик. Входи можуть мати параметри. Оператори виклику входу і оператори прийняття входу є основним засобом синхронізації завдань і обміну даними між завданнями.
1.2. Специфікація і тіло задачі
Властивості кожного завдання визначаються таким, що відповідає задачним модулем, який складається із специфікації завдання і тіла завдання. Завдання не може відкомпілюватися самостійно. Тому для компіляції завдання має бути поміщене в підпрограму або пакет. Загальна форма специфікації завдання :
TASK имя_задачи IS
ENTRY имя_входа_1(формальный_параметр_1: имя_типа_1;………формальный_параметр_K: имя_типа_K);
.
.
.
ENTRY имя_входа_N(формальный_параметр_L:имя_типа_L; …… формальный_параметр_M: имя_типа_M);
END имя_задачи;
Ця форма специфікації визначає завдання з входами, що мають формальні параметри. До цього завдання можуть звертатися інші завдання, викликаючи її входи. Конструкція
ENTRY имя_входа(формальные параметры);
називається описом входу. Вхід може мати формальні параметри видів IN(тільки для читання), OUT(тільки для запису) або IN OUT(і для читання, і для запису). Якщо вид формального параметра не заданий, то за умовчанням набирає вигляду IN.
1.3. Задачні типи
Задачні типи полегшують опис однакових завдань, оскільки декілька однакових завдань можуть бути описані разом в масиві або індивідуально. Специфікація завдання, що починається зарезервованими словами TASK TYPE, описує задачний тип. Наприклад, опишемо задачний тип До:
TASK TYPE K IS
ENTRY P1;
END K;
Після опису задачного типу можна описувати об’єкти цього типу. Значення об’єкту задачного типу є завданням, яке має ті ж входи, що і відповідний задачний тип, і виконання якої визначене відповідним тілом завдання. Наприклад, опис
F1, F2 : K;
визначає два завдання( два об’єкти задачного типу ) F1 і F2. Ці завдання стають активними безпосередньо перед виконанням першого оператора підпрограми або перед виконанням пакету, в якому ці завдання описані.
1.4. Захищені модулі
Ада 95 характеризується появою в ній ще одного виду програмних модулів – захищених модулів( protected units ). Їх призначення – розширення можливостей мови при програмуванні паралельних процесів, зокрема – для вирішення проблеми доступу до загальних ресурсів. Крім того, захищені модулі забезпечують підтримку різних парадигм систем реального часу.
У Аді 83 механізм рандеву був єдиним засобом, що використався для організації як міжзадачного взаимодей¬ствия, так і для синхронизированого доступу до загальних даних( shared data). Досвід використання мови показав, що це не завжди зручно, і зажадав перегляду методів синхронізації і введення в мову додаткових коштів, що забезпечують ефективніші засоби роботи із загальними даними.
У Аді 95 ця проблема розв’язана за допомогою додавання в мову орієнтованого на дані механізму синхронізації, заснованого на концепції захищених об’єктів. Операції над захищеними обьектами дозволяють декільком завданням синхронізувати свої дії при роботі із загальними даними.
Концепція захищених модулів заснована на механізмах критичних умовних областей( critical region condition ) і умовних моніторів( condition monitors ) [14,15 ]. Ідея монітора, запропонована Б. Хансеном і розвинена С. Хоаром, грунтується на обьединении змінних, що описують загальний ресурс, і дій, що визначають способи доступу до ресурсу.
Монітор – програмний модуль, що містить змінні і процедури для роботи з ними, причому доступ до змінних можливий тільки через процедури монітора. Такій концепції до певної міри відповідає в Аді реалізація пакетів. Проте призначення монітора не лише в інкапсуляції. Монітор – засіб розподілу ресурсів і взаємодії процесів. Це призначення монітора реалізується за допомогою властивостей, якими наділені процедури монітора. Характерна особливість процедур монітора -взаимное виключення ними один одного. У будь-який момент часу може виконуватися тільки одна процедура монітора. Якщо деякий процес викликав і виконує процедуру монітора, то жоден інший процес не може виконувати процедури монітора. При спробі виклику іншим процесором цій же або іншої процедури монітора
Специфікація і тіло захищеного модуля
Явяляючись ще одним видом програмного модуля в Аді, защи¬щенный модуль має уніфіковану структуру, прийняту в мові . тобто складається із специфікації і тіла.
PROTECTED [TYPE] Имя_Защищенного_Модуля
[Дискриминант ] IS
– – Описание_Защищенных_Операций [ PRIVATE 1
– – Описание _Защищенных_Элементов
END Имя_Защищенного_Модуля;
Тут Опис Захищених _Операції – опис захищених підпрограм, захищених входів, контекстів представлення ; Опис_Захищених_Елементів – опис захищених операцій і опис компонент.
Захищений тип є лімітованим типом. Він може мати дискримінант, аналогічно задачному типу, що дозволяє мінімізувати число операцій при ініціалізації захищених обьектов.
Захищені операції – це функції. процедури і входи, описані в специфікації захищеного модуля. Приватна частина специфікації обмежує видимість захищених елементів : операцій і обьектов, описаних в ній. Загальні дані, доступ до яких координується захищеним модулем, описуються в приватній частині його специфікації.
Захищені функції забезпечують доступ тільки по читанню компонентів захищеного модуля.
Захищені процедури забезпечують ексклюзивне читання і запис компонент захищеного модуля.
Захищені входи забезпечують ті ж фунции, що і входи завдань, додатково реалізовуючи за допомогою бар’єрів ексклюзивний доступ до тіла захищеного входу.
1.5. Семафори в мові Ада
У стандарті мови Ада95 механізм семафорів подано у вигляді пакета Synchronous Task Control в додатку Annex D: Real-Time Systems. Пакет реалізує механізм семафорів таким чином. Семафорний тип забезпечується приватним типом Suspension_Object, операції Р{5) і v{S) реалізовані за допомогою процедур Suspend_Until_True () і Set_True (). Використовується бінарний логічний семафор, тобто семафорні змінні типу Suspension_Object набувають значень false і true. Крім указаних процедур, в пакеті реалізовані допоміжні процедури Set_False() для встановлення значення семафора в false і Current state() для зчитування поточного значення семафора. Специфікація пакета:
package Ada.Synchronous_Task_Control іs
type Suspension_Object is limited private;
procedure Set_True(S : in out Suspension_Object);
procedure Set_False(S : in out Suspension_Object);
function Current_State(S : Suspension_Object) return Boolean;
procedure Suspend_Until_True(S : in out Suspension_Object);
private
…
end Ada.Synchronous_Task_Control;
ВИСНОВКИ ДО РОЗДІЛУ 1.
1. Ада має досить ефективні і прості у використанні засоби паралельного програмування, включаючи задачі, захищені модулі, монітори та семафори.
2. За допомогою засобів Ада можна будувати паралельні програми для систем з локальною та спільною памяттю.
РОЗДІЛ 2. Розробка ПЗ для ПОС
2.1. Розробка паралельного математичного алгоритму
1. AH = B*(MC*MDH) – XH. ОР: B, MC.
N –розмірність матриць,
р – кількість процесорів.
H = N/p – оброблювана частина.
2.2. Розробка алгоритмів задач
1. Если(rank==0) ввод B, MD.
2. Если(rank==3) ввод MC, X.
3. Если(rank == 0).
Передать T1 B, MD3H.
Принять от T1 MC, XH.
4. Если(rank == 1).
Принять от T0 B, MD3H.
Принять от T2 MC, X2H.
Передать T0 MC, XH.
Передать T2 B, MD2H.
5. Если(rank == 2).
Принять от T3 MC, X3H.
Передать T1 MC, X2H.
Принять от T1 B, MD2H.
Передать T3 B, MDH.
6. Если(rank == 3).
Передать T2 MC, X3H.
Принять от T2 B, MDH.
7. Счёт AH = B (MC * MDH) – XH.
8. Если(rank == 0).
Передать T1 AH.
9. Если(rank == 1).
Принять от T0 AH.
Принять от T2 A2H.
10. Если(rank == 2).
Принять от T3 AH.
Передать T1 A2H.
11. Если(rank == 3).
Передать T2 AH.
12. Если(rank == 1) вывод A.
2.3. Розробка схеми взаємодії задач
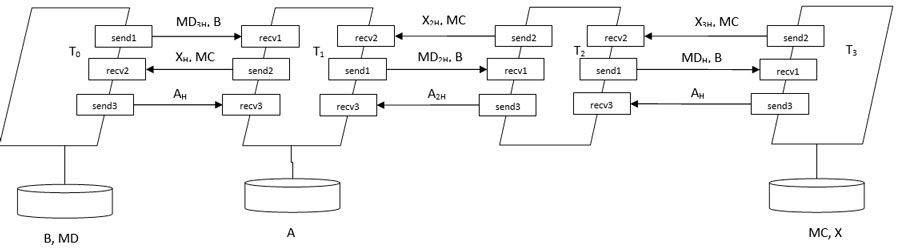
2.4. Розробка програми
Лістинг програми представлений в додатку Е. Тут представимо модулі, використані в програмі.
· Library.cpp – бібліотека використаних функцій. Сюди входять функції вводу-виводу та матрично-векторні операції, настроювані за номером оброблюваної частини.
· Lab4 – власне визначення виконуваної задачі.
ВИСНОВКИ ДО РОЗДІЛУ 2.
1. Розроблений алгоритм задачі для процесів на мові C для ПОС з ЛП.
2. Програма з локальною пам’яттю реалізована за допомогою технології MPI.
3. По алгоритму розроблено структурну схему взаємодії завдань, за допомогою якої легко написати програму.
РОЗДІЛ 3. ПРОВЕДЕННЯ ЭКСПЕРЕМЕНТАЛЬНЫХ ДОСЛІДЖЕНЬ
3.1. Дослідження ефективності реальної ПОС
В ході виконання роботи була розроблена програма на мові C, що вирішує задану задачу A = B * (M*MD) – X на ПОС. Усі експерименти проводилися на високопродуктивній системі Intel® Core™ i7-2630QM OП 16384. При проведенні експериментів був проведений вимір часу виконання заданого вираження для різної кількості процесорів P (1, 2, 3, 4) і різній розмірності матриць N (N=1000, 1500, 2000, 2500). Результати виконання програми приведені в таблиці 3.1
Таблиця. 3.1. Час виконання програми.
| p | ||||
| N | 1 | 2 | 3 | 4 |
| 1000 | 26 | 14 | 9 | 7 |
| 1500 | 93 | 47 | 32 | 24 |
| 2000 | 231 | 117 | 78 | 59 |
| 2500 | 467 | 235 | 156 | 118 |
В результаті проведення експериментів були підраховані коефіцієнти ефективності і прискорення (таблиця 3.3).
Таблиця. 3.3. Коефіцієнти прискорення і ефективності.
| p | ||||||
| N | 2 | 3 | 4 | |||
| КУ | КЭ | КУ | КЭ | КУ | КЭ | |
| 1000 | 1,85 | 92,5 | 2,88 | 96,0 | 3,71 | 92,7 |
| 1500 | 1,97 | 98,5 | 2,90 | 96,6 | 3,87 | 96,7 |
| 2000 | 1,97 | 98,5 | 2,96 | 98,6 | 3,91 | 97,7 |
| 2500 | 1,98 | 99,0 | 2,99 | 96,6 | 3,95 | 98,7 |
3.2. Статистична обробка результатів
3.2.1. Залежність часу виконання завдання від числа процесорів
За результатами експериментів був побудований графік залежності часу виконання від числа процесорів для загальної пам’яті. Графік представлений на рисунку 3.1.
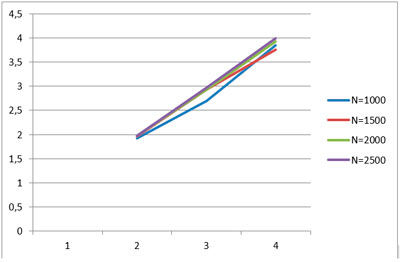
Рис. 3.1 Залежність часу виконання від числа процесорів в системі із спільною пам’яттю.
3.2.2. Залежність коефіцієнта прискорення від числа процесорів
За результатами експериментів був побудований графік залежності коефіцієнта прискорення від числа процесорів. Графіки представлені на рисунку 3.3.
Рис. 3.3 Залежність коефіцієнта прискорення від числа процесорів в системі із загальною пам’яттю
ВИСНОВКИ ДО РОЗДІЛУ 3.
1. По графіках на малюнку 3.3 можна сказати, що залежність коефіцієнта прискорення від числа процесорів має лінійний характер.
2. З таблиці 3.3 можна сказати, що коефіцієнт ефективності зростає зі зростанням розмірності матриць. Це пов’язано зі зменшенням часу пересилок даних між процесорами по відношенню до часу паралельного обчислення функції.
3. При достатньо великих N>Nгр у зв’язку з обмеженістю оперативної памяті час виконання програми залежить від числа хеш-промахів, а значить і звертань до файлу підкачки. В цьому випадку строгої закономірності немає, але функція часу обмежена зверху прямою, з кутовим коефіцієнтом в десятки разів більшим, аніж для N<Nгр. Це пов’язана зі швидкістю звернення до жорсткого носію.
ВИСНОВКИ
При виконанні курсової роботи було зроблено наступне:
1. Детальний аналіз засобів паралельного програмування в мові Ада.
2. Розроблено програмне забезпечення для вирішення поставленого завдання на ПОС заданої структури. Початкове завдання було проаналізоване на паралелізм, був написаний паралельний алгоритм рішення задачі, визначені необхідні для вирішення поставленого завдання засобу, розроблені алгоритми основної програми і задач. Програмний продукт був реалізований на мові C з використанням бібліотеки MPI.
3. Було проведено експериментальне дослідження, метою якого було отримання практичних результатів роботи створеного програмного продукту. Отримані дані були оброблені і проаналізовані на предмет відповідності теоретичних викладенням.
4. Падіння коефіцієнту прискорення зі збільшенням кількості процесорів пов’язано з недостатньою пропускною здатністю пам’яті. Коефіцієнт прискорення є високим, через те, що задані векторно-матричні операції в цілому є частково-паралельні, але окремі дії є повністю паралельними.
Література
1. Жуков И.А., Корочкин А.В. Параллельные и распределенные вы-числения. Науч. пособ. – К.: «Корнейчук», 2005. – 226 с.
2. Жуков И.А., Корочкин А.В. Параллельные и распределенные вы-числения. Лабораторный практикум. Учебно – методическое пособие. К.: «Корнейчук», 2008. – 224 с.
3. Интерфейс передачи сообщений MPI
4. Нэш Трей. C# 2008. Ускоренный курс для профессионалов. Пер. с англ. – М.: ООО «И.Д. Вильямс». 2008. – 576.
5. Работа с потоками в С#
6. C++ Потоки в Win32
7. Эндрю Троелсен – С# и платформа .NET. Библиотека программи-ста – СПб.: Питер, 2004. – 796с.
8. Pat Niemeyer, Jonathan Knudsen “Learning Java” O’Reilly, 2000
9. MPI – программный инструмент для параллельных вычислений
10. Параллельные вычисления
11. Гергель В.П., Стронгин Р.Г. Основы параллельных вычислений для многопроцессорных вычислительных систем. – Н.Новгород, ННГУ, 2001.- 184 с.
12. Деммель Дж. Вычислительная линейная алгебра. Теория и прило-жения: Пер. с англ. – М.: Мир, 2001. – 430 с.
13. Kumar V., Grama A., Gupta A., Karypis G. Introduction to Parallel Computing. – The Benjamin/Cummings Publishing Company, Inc., 1994.- 346 p.
14. Коммуникационные библиотеки и интерфейсы (API) параллельного программирования
15. Параллельное программирование
17. OpenMP
18. Технологии параллельного программирования. Message Passing Interface (MPI)
19. Threading Tutorial(C#)[
20. Threading in C#
21. Java 2 Platform SE v1.3.1: Class Thread
22. Схематичные примеры MPI-программ
Додатки
Додаток А.Блок-схема виконання задачі
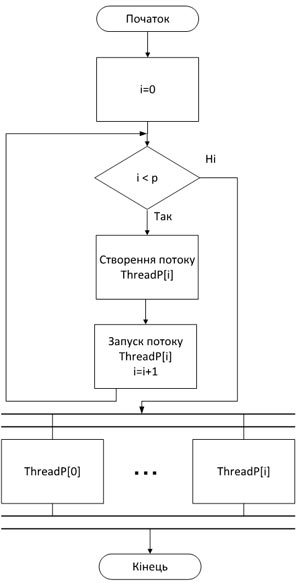
Додаток Б. Блок-схема 2-го процесу задачі
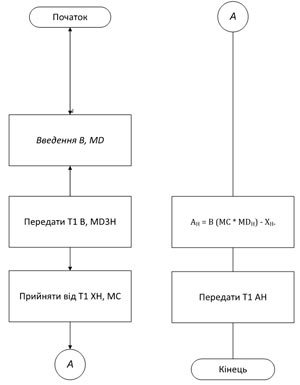
Додаток В. Лістинг задачі для P=4
library.h:
#include <stdio.h>
#include <limits.h>
//параметры матриц
const int N = 12; //размер
const int P = 4; //число процессоров
const int H = N/P; //кусок
void TransponMatrix(int M[]);
void SubVector(int V1[], int V2[], int VR[], int currH);
void MulMatrix(int M1[], int M2[], int MR[], int currH);
void MulVectorMatrix(int V1[], int M2[], int VR[], int currH);
void InputCount(int *count);
void InputVector(int V[]);
void InputMatrix(int M[]);
void OutputVector(int V[]);
void OutputMatrix(int M[]);
library.cpp:
#include “stdafx.h”
#include “Library.h”
void TransponMatrix(int M[]){
for(int i = 0; i < N; i++){
for(int j = i; j < N; j++){
int buf = M[i*N+j];
M[i*N+j] = M[j*N+i];
M[j*N+i] = buf;
}
}
}
void MulMatrix(int M1[], int M2[], int MR[], int currH){
for(int j = currH*H + 0; j < currH*H + H; j++){
for(int i = 0; i < N; i++){
MR[i*N+j] = 0;
for(int k = 0; k < N; k++){
MR[i*N+j] += M1[i*N+k] * M2[j*N+k];
}
}
}
}
void MulVectorMatrix(int V1[], int M2[], int VR[], int currH){
for(int j = currH*H + 0; j < currH*H + H; j++){
VR[j] = 0;
for(int k = 0; k < N; k++){
VR[j] += V1[k] * M2[k*N+j];
}
}
}
void SubVector(int V1[], int V2[], int VR[], int currH){
for(int i = currH*H + 0; i < currH*H + H; i++){
VR[i] = V1[i] – V2[i];
}
}
void InputCount(int *count){
*count = 1;
}
void InputMatrix(int M[]){
for (int i = 0; i < N; i++){
for (int j = 0; j < N; j++){
M[i*N+j] = 1;
}
}
}
void InputVector(int V[]){
for (int i = 0; i < N; i++){
V[i] = 1;
}
}
void OutputVector(int V[]){
//if(N<=12)
for (int i = 0; i < N; i++){
printf(“%3i “, V[i]);
}
printf(“\n”);
}
void OutputMatrix(int M[]){
//if(N<=12)
for (int i = 0; i < N; i++){
for (int j = 0; j < N; j++){
printf(“%3i “, M[i*N+j]);
}
printf(“\n”);
}
}
Lab4.cpp:
//topology: linear
//function: A = B(MC*MD) – X
#pragma comment (lib, “mpi.lib”)
#include “stdafx.h”
#include <mpi.h>
#include “library.h”
//переменные узла
int *MC = new int[N*N];
int *MD = new int[N*N];
int *MR = new int[N*N];
int *B = new int[N];
int *R = new int[N];
int *X = new int[N];
int *A = new int[N];
int rank; //номер задачи
int size; //число задач (общее)
MPI_Status st; //статус передачи
int main(int args, char* argv[]){
MPI_Init(&args, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
printf(“T%d started.\n”, rank);
//ввод
if(rank == 0){
InputVector(B);
InputMatrix(MD);
TransponMatrix(MD);
}
if(rank == 3){
InputVector(X);
InputMatrix(MC);
}
//передача MB, MC
switch(rank){
case 0:
MPI_Send(MD+1*H*N, 3*H*N, MPI_INT, 1, 0, MPI_COMM_WORLD);
MPI_Send(B , N, MPI_INT, 1, 1, MPI_COMM_WORLD);
MPI_Recv(MC, N*N, MPI_INT, 1, 0, MPI_COMM_WORLD, &st);
MPI_Recv(X , 1*H, MPI_INT, 1, 1, MPI_COMM_WORLD, &st);
break;
case 1:
MPI_Recv(MD+1*H*N, 3*H*N, MPI_INT, 0, 0, MPI_COMM_WORLD, &st);
MPI_Recv(B , N, MPI_INT, 0, 1, MPI_COMM_WORLD, &st);
MPI_Recv(MC, N*N, MPI_INT, 2, 0, MPI_COMM_WORLD, &st);
MPI_Recv(X , 2*H, MPI_INT, 2, 1, MPI_COMM_WORLD, &st);
MPI_Send(MC, N*N, MPI_INT, 0, 0, MPI_COMM_WORLD);
MPI_Send(X , 1*H, MPI_INT, 0, 1, MPI_COMM_WORLD);
MPI_Send(MD+2*H*N, 2*H*N, MPI_INT, 2, 0, MPI_COMM_WORLD);
MPI_Send(B , N, MPI_INT, 2, 1, MPI_COMM_WORLD);
break;
case 2:
MPI_Recv(MC, N*N, MPI_INT, 3, 0, MPI_COMM_WORLD, &st);
MPI_Recv(X , 3*H, MPI_INT, 3, 1, MPI_COMM_WORLD, &st);
MPI_Send(MC, N*N, MPI_INT, 1, 0, MPI_COMM_WORLD);
MPI_Send(X , 2*H, MPI_INT, 1, 1, MPI_COMM_WORLD);
MPI_Recv(MD+2*H*N, 2*H*N, MPI_INT, 1, 0, MPI_COMM_WORLD, &st);
MPI_Recv(B , N, MPI_INT, 1, 1, MPI_COMM_WORLD, &st);
MPI_Send(MD+3*H*N, 1*H*N, MPI_INT, 3, 0, MPI_COMM_WORLD);
MPI_Send(B , N, MPI_INT, 3, 1, MPI_COMM_WORLD);
break;
case 3:
MPI_Send(MC, N*N, MPI_INT, 2, 0, MPI_COMM_WORLD);
MPI_Send(X , 3*H, MPI_INT, 2, 1, MPI_COMM_WORLD);
MPI_Recv(MD+3*H*N, 1*H*N, MPI_INT, 2, 0, MPI_COMM_WORLD, &st);
MPI_Recv(B , N, MPI_INT, 2, 1, MPI_COMM_WORLD, &st);
break;
}
//счёт
MulMatrix(MC, MD, MR, rank);
MulVectorMatrix(B, MR, R, rank);
SubVector(R, X, A, rank);
//передача A
switch(rank){
case 0:
MPI_Send(A , 1*H, MPI_INT, 1, 2, MPI_COMM_WORLD);
break;
case 1:
MPI_Recv(A , 1*H, MPI_INT, 0, 2, MPI_COMM_WORLD, &st);
MPI_Recv(A+2*H, 2*H, MPI_INT, 2, 2, MPI_COMM_WORLD, &st);
break;
case 2:
MPI_Recv(A+3*H, 1*H, MPI_INT, 3, 2, MPI_COMM_WORLD, &st);
MPI_Send(A+2*H, 2*H, MPI_INT, 1, 2, MPI_COMM_WORLD);
break;
case 3:
MPI_Send(A+3*H, 1*H, MPI_INT, 2, 2, MPI_COMM_WORLD);
break;
}
//вывод
if(rank == 1){
OutputVector(A);
}
printf(“T%d finished.\n”, rank);
MPI_Finalize();
return 0;
}
Додаток В. Лістинг задачі для P=8
Lab8.cpp:
//Korsakow K.
//ZIO-71
//topology: linear
//function: A = B(MC*MD) – X
#pragma comment (lib, “mpi.lib”)
#include “stdafx.h”
#include <mpi.h>
#include “library.h”
//переменные узла
int *MC = new int[N*N];
int *MD = new int[N*N];
int *MR = new int[N*N];
int *B = new int[N];
int *R = new int[N];
int *X = new int[N];
int *A = new int[N];
int rank; //номер задачи
int size; //число задач (общее)
MPI_Status st; //статус передачи
int main(int args, char* argv[]){
MPI_Init(&args, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
printf(“T%d started.\n”, rank);
//ввод
if(rank == 0){
InputVector(B);
InputMatrix(MD);
TransponMatrix(MD);
}
if(rank == 3){
InputVector(X);
InputMatrix(MC);
}
//передача MB, MC
switch(rank){
case 0:
MPI_Send(MD+1*H*N, 7*H*N, MPI_INT, 1, 0, MPI_COMM_WORLD);
MPI_Send(B , N, MPI_INT, 1, 1, MPI_COMM_WORLD);
MPI_Recv(MC, N*N, MPI_INT, 1, 0, MPI_COMM_WORLD, &st);
MPI_Recv(X , 1*H, MPI_INT, 1, 1, MPI_COMM_WORLD, &st);
break;
case 1:
MPI_Recv(MD+1*H*N, 7*H*N, MPI_INT, 0, 0, MPI_COMM_WORLD, &st);
MPI_Recv(B , N, MPI_INT, 0, 1, MPI_COMM_WORLD, &st);
MPI_Recv(MC, N*N, MPI_INT, 2, 0, MPI_COMM_WORLD, &st);
MPI_Recv(X , 2*H, MPI_INT, 2, 1, MPI_COMM_WORLD, &st);
MPI_Send(MC, N*N, MPI_INT, 0, 0, MPI_COMM_WORLD);
MPI_Send(X , 1*H, MPI_INT, 0, 1, MPI_COMM_WORLD);
MPI_Send(MD+2*H*N, 6*H*N, MPI_INT, 2, 0, MPI_COMM_WORLD);
MPI_Send(B , N, MPI_INT, 2, 1, MPI_COMM_WORLD);
break;
case 2:
MPI_Recv(MC, N*N, MPI_INT, 3, 0, MPI_COMM_WORLD, &st);
MPI_Recv(X , 3*H, MPI_INT, 3, 1, MPI_COMM_WORLD, &st);
MPI_Send(MC, N*N, MPI_INT, 1, 0, MPI_COMM_WORLD);
MPI_Send(X , 2*H, MPI_INT, 1, 1, MPI_COMM_WORLD);
MPI_Recv(MD+2*H*N, 6*H*N, MPI_INT, 1, 0, MPI_COMM_WORLD, &st);
MPI_Recv(B , N, MPI_INT, 1, 1, MPI_COMM_WORLD, &st);
MPI_Send(MD+3*H*N, 5*H*N, MPI_INT, 3, 0, MPI_COMM_WORLD);
MPI_Send(B , N, MPI_INT, 3, 1, MPI_COMM_WORLD);
break;
case 3:
MPI_Send(MC, N*N, MPI_INT, 2, 0, MPI_COMM_WORLD);
MPI_Send(X , 3*H, MPI_INT, 2, 1, MPI_COMM_WORLD);
MPI_Recv(MD+3*H*N, 5*H*N, MPI_INT, 2, 0, MPI_COMM_WORLD, &st);
MPI_Recv(B , N, MPI_INT, 2, 1, MPI_COMM_WORLD, &st);
MPI_Send(MD+4*H*N, 4*H*N, MPI_INT, 4, 0, MPI_COMM_WORLD);
MPI_Send(B , N, MPI_INT, 4, 1, MPI_COMM_WORLD);
MPI_Send(MC, N*N, MPI_INT, 4, 2, MPI_COMM_WORLD);
MPI_Send(X+4*H, 4*H, MPI_INT, 4, 3, MPI_COMM_WORLD);
break;
case 4:
MPI_Recv(MD+4*H*N, 4*H*N, MPI_INT, 3, 0, MPI_COMM_WORLD, &st);
MPI_Recv(B , N, MPI_INT, 3, 1, MPI_COMM_WORLD, &st);
MPI_Recv(MC, N*N, MPI_INT, 3, 2, MPI_COMM_WORLD, &st);
MPI_Recv(X+4*H, 4*H, MPI_INT, 3, 3, MPI_COMM_WORLD, &st);
MPI_Send(MD+5*H*N, 3*H*N, MPI_INT, 5, 0, MPI_COMM_WORLD);
MPI_Send(B , N, MPI_INT, 5, 1, MPI_COMM_WORLD);
MPI_Send(MC, N*N, MPI_INT, 5, 2, MPI_COMM_WORLD);
MPI_Send(X+5*H, 3*H, MPI_INT, 5, 3, MPI_COMM_WORLD);
break;
case 5:
MPI_Recv(MD+5*H*N, 3*H*N, MPI_INT, 4, 0, MPI_COMM_WORLD, &st);
MPI_Recv(B , N, MPI_INT, 4, 1, MPI_COMM_WORLD, &st);
MPI_Recv(MC, N*N, MPI_INT, 4, 2, MPI_COMM_WORLD, &st);
MPI_Recv(X+5*H, 3*H, MPI_INT, 4, 3, MPI_COMM_WORLD, &st);
MPI_Send(MD+6*H*N, 2*H*N, MPI_INT, 6, 0, MPI_COMM_WORLD);
MPI_Send(B , N, MPI_INT, 6, 1, MPI_COMM_WORLD);
MPI_Send(MC, N*N, MPI_INT, 6, 2, MPI_COMM_WORLD);
MPI_Send(X+6*H, 2*H, MPI_INT, 6, 3, MPI_COMM_WORLD);
break;
case 6:
MPI_Recv(MD+6*H*N, 2*H*N, MPI_INT, 5, 0, MPI_COMM_WORLD, &st);
MPI_Recv(B , N, MPI_INT, 5, 1, MPI_COMM_WORLD, &st);
MPI_Recv(MC, N*N, MPI_INT, 5, 2, MPI_COMM_WORLD, &st);
MPI_Recv(X+6*H, 2*H, MPI_INT, 5, 3, MPI_COMM_WORLD, &st);
MPI_Send(MD+7*H*N, 1*H*N, MPI_INT, 7, 0, MPI_COMM_WORLD);
MPI_Send(B , N, MPI_INT, 7, 1, MPI_COMM_WORLD);
MPI_Send(MC, N*N, MPI_INT, 7, 2, MPI_COMM_WORLD);
MPI_Send(X+7*H, 1*H, MPI_INT, 7, 3, MPI_COMM_WORLD);
break;
case 7:
MPI_Recv(MD+7*H*N, 1*H*N, MPI_INT, 6, 0, MPI_COMM_WORLD, &st);
MPI_Recv(B , N, MPI_INT, 6, 1, MPI_COMM_WORLD, &st);
MPI_Recv(MC, N*N, MPI_INT, 6, 2, MPI_COMM_WORLD, &st);
MPI_Recv(X+7*H, 1*H, MPI_INT, 6, 3, MPI_COMM_WORLD, &st);
break;
}
//счёт
MulMatrix(MC, MD, MR, rank);
MulVectorMatrix(B, MR, R, rank);
SubVector(R, X, A, rank);
//передача A
switch(rank){
case 0:
MPI_Send(A , 1*H, MPI_INT, 1, 4, MPI_COMM_WORLD);
break;
case 1:
MPI_Recv(A , 1*H, MPI_INT, 0, 4, MPI_COMM_WORLD, &st);
MPI_Recv(A+2*H, 6*H, MPI_INT, 2, 4, MPI_COMM_WORLD, &st);
break;
case 2:
MPI_Recv(A+3*H, 5*H, MPI_INT, 3, 4, MPI_COMM_WORLD, &st);
MPI_Send(A+2*H, 6*H, MPI_INT, 1, 4, MPI_COMM_WORLD);
break;
case 3:
MPI_Recv(A+4*H, 4*H, MPI_INT, 4, 4, MPI_COMM_WORLD, &st);
MPI_Send(A+3*H, 5*H, MPI_INT, 2, 4, MPI_COMM_WORLD);
break;
case 4:
MPI_Recv(A+5*H, 3*H, MPI_INT, 5, 4, MPI_COMM_WORLD, &st);
MPI_Send(A+4*H, 4*H, MPI_INT, 3, 4, MPI_COMM_WORLD);
break;
case 5:
MPI_Recv(A+6*H, 2*H, MPI_INT, 6, 4, MPI_COMM_WORLD, &st);
MPI_Send(A+5*H, 3*H, MPI_INT, 4, 4, MPI_COMM_WORLD);
break;
case 6:
MPI_Recv(A+7*H, 1*H, MPI_INT, 7, 4, MPI_COMM_WORLD, &st);
MPI_Send(A+6*H, 2*H, MPI_INT, 5, 4, MPI_COMM_WORLD);
break;
case 7:
MPI_Send(A+7*H, 1*H, MPI_INT, 6, 4, MPI_COMM_WORLD);
break;
}
//вывод
if(rank == 1){
OutputVector(A);
}
printf(“T%d finished.\n”, rank);
MPI_Finalize();
return 0;
}